PicsLikeThat
How to Use PicsLikeThat?

The image search system incrementally presents users with images identified as visually and/or semantically similar. This advanced method delivers significantly better search results compared to the traditional combination of keyword and visual similarity searches. For the first time, this approach effectively distinguishes between images of homographs.
The implementation of this system works with over 15 million images from Fotolia. Using picsLikeThat is straightforward: after an initial keyword search, up to 500 images are visually sorted and displayed. The sorting makes it easy to identify images that closely match the desired outcome. By repeatedly double-clicking on images that resemble the desired result, the system iteratively refines the search using three categories:
- Visually similar images with the same keyword,
- images with keywords related to those of the clicked image, and
- images with semantic relationships to the clicked image, derived from user click paths.
A unique feature of this search approach is that user clicks generate a network of image relationships. This network does not rely on keywords, making it language-independent. As the system learns new visual relationships, search results are continuously enhanced. Users, without realizing it, help to organize and "clean up" the entire image set with their searches. Each click expands and refines this network of linked images.
Collecting Semantic Information
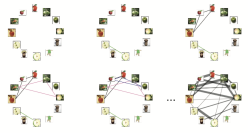
The principle of collecting semantic image relationships is based on these ideas:
- Users do not like to give feedback. However, they will mark candidate images in order to improve the quality of their retrieved image search result.
- By selecting a set of candidate images a user expresses the fact that according to his desired search result these images do share some common semantic meaning.
- Even though the particular semantic relationship is not known to the system, the selection of candidate sets - when collected over many searches - can be used to semi-automatically model the semantic inter-image relationships.
- Inter-image relationships are modeled with weighted links, that describe how often two particular images have been selected together as part of a candidate set.
- Semantic filtering can be achieved by retrieving those images having the highest link weight.
